

Золотой век дезинформации
Просмотр ленты новостей часто напоминает игру «Правда или ложь». Какую-то ложную информацию действительно легко распознать. Вроде сообщений о том, что первая леди США Меланья Трамп хотела вызвать экзорциста, чтобы тот очистил Белый дом от демонов Обамы. В других случаях авторская задумка слишком хорошо вяжется с фактами. Федеральная комиссия по связи совершила рейдерских захват CNN? Полицейские обнаружили лабораторию метамфетамина в магазине Walmart в штате Алабама? Нет и нет. Но любого, кто просматривает множество постов каждый день, можно легко одурачить.
Мы живем в золотой век дезинформации. В Twitter ложь распространяется куда быстрее правды. Согласно предвыборным прогнозам BuzzFeed News, в преддверии президентских выборов в 2016 году в США самые популярные фиктивные статьи получили больше репостов, реакций и комментариев в Facebook, чем лучшие настоящие новости.
«До эпохи интернета вы не смогли бы сидеть на чердаке и создавать теории заговора в массовом масштабе», — пишет Лука де Альфаро, ученый в области компьютерных технологий из Калифорнийского университета в Санта-Крусе. Но с социальными сетями слишком легко торговать ложью — будь то ложь из Disinfomedia, компании, владеющей несколькими фиктивными новостными сайтами, или шутка подростков из Македонии, которые зарабатывали деньги, набирая популярные поддельные новости во время выборов в 2016 году.
Ложь просто нравится людям больше, чем правда
Большинство интернет-пользователей непреднамеренно транслирует ложь. Информационная перегрузка и ограниченный охват всего новостного сегмента веб-серфером не способствуют тщательной проверке фактов. Ну и личные предпочтения пользователей играют свою роль.
«Когда речь идет о нефильтрованной информации, вероятно, люди выберут ту, что соответствует их собственному мышлению, даже если эта информация неверна», — уверена Фабиана Золло, специалист по компьютерным технологиям из Университета Ка’Фоскари в Венеции. Она изучает процесс распространения информации в социальных сетях.
Преднамеренная или нет, передача дезинформации имеет серьезные последствия. Поддельные новости не просто угрожают легитимности выборов и подрывают доверие общественности к настоящим новостям. Это угрожает жизни. Ложные слухи, которые распространялись в WhatsApp, например, подстрекали линчевание в Индии, в результате чего погибло десять людей.
Чтобы отсортировать фальшивые новости от правды, программисты строят автоматизированные системы, проверяющие правдивость онлайн-историй. Компьютерная программа рассматривает некоторые характеристики статьи или способ ее проникновения в соцсети. Компьютеры, считывающие определенные знаки, предупреждают людей, выполняющих окончательную проверку. Но автоматические инструменты поиска лжи «все еще находятся в зачаточном состоянии», — отмечает ученый-биолог Джованни Лука Чампалья из Индианского Университета в Блумингтоне.
Исследователи изучают, какие факторы наиболее надежно указывают на поддельные новости. К сожалению, у них нет точного набора критериев для проверки. Некоторые программисты полагаются на СМИ или государственные агентства печати, чтобы определить, какие истории верны или нет, а другие — на списки фальшивых новостей в социальных сетях. Поэтому исследования в этой области являются чем-то вроде бесплатного пособия для всех.
Но команды по всему миру продвигаются вперед, потому что интернет — это пожарный шланг информации. И просить людей, занимающихся факт-чекингом, следить за этим, — все равно что направить этот шланг на фильтр для питьевой воды. «Это своего рода шок, — говорит Алекс Каспрак, научный писатель Snopes.com, старейшего и самого крупного онлайн-сайта проверки фактов. — В интернете огромное количество фальсифицированной информации».


Фейки пишут другими словами
Когда дело доходит до проверки содержания новостей напрямую, есть два основных способа доказать, соответствует ли история закону о мошенничестве: что говорит автор и как он говорит об этом.
Чампалья и его коллеги автоматизировали эту утомительную задачу с помощью программы, которая проверяет, насколько тесно связаны субъект и объект заявления. Для этого программа использует обширную сеть утверждений, построенных из фактов, найденных в инфобоксах в правой части каждой страницы Википедии.
В сети, разработанной группой Чампалья, два слова связаны друг с другом, если одно из утверждений появилось в инфобоксах другого. Чем меньше степень разделения субъекта и объекта в этой сети и чем более конкретными являются промежуточные слова, связывающие субъект и объект, тем более вероятно, что компьютерная программа определит это утверждение как истинное.
Возьмите ложное утверждение «Барак Обама — мусульманин». В сети Чампальи существуют семь степеней разделения между «Обамой» и «Исламом», в том числе очень общие слова, такие как «Канада», которые связаны со многими другими утверждениями. Учитывая этот длинный извилистый маршрут, автоматическая проверка фактов, описанная в 2015 году в PLOS ONE, посчитала, что Обама вряд ли станет мусульманином.
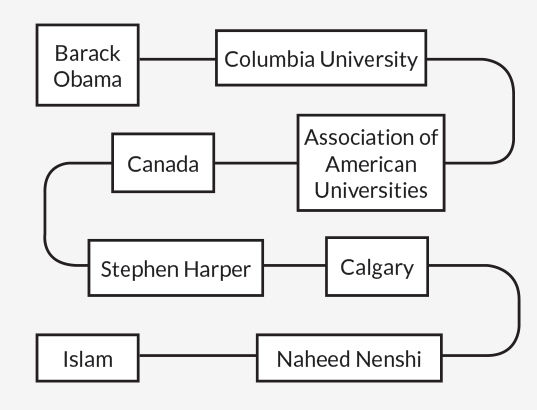
Но оценка достоверности высказываний, основанных на такого рода разделении субъекта-объекта, имеет свои пределы. Например, система решила, что бывший президент Джордж Буш-младший женат на Лоре Буш. Отлично. Он также решил, что Джордж Буш, вероятно, женат на Барбаре Буш, его матери. Не так успешно. Чампалья и его коллеги работали над тем, чтобы дать своей программе более тонкий взгляд на отношения между словами в сети.
Проверка каждого утверждения в статье — это не единственный способ определения фейков. Стиль письма может также помочь. Бенджамин Хорн и Сибель Адали, компьютерщики из Политехнического института имени Ренсселера в Трое, Нью-Йорк, проанализировали 75 достоверных статей из СМИ, которые, по мнению Business Insider, заслуживают наибольшего доверия, а также 75 ложных историй, которые находятся в черном списке дезинформирующих веб-сайтов.
По сравнению с настоящими новостями, фейковые статьи, как правило, были короче, с повторами и с большим количеством наречий. У поддельных историй также было меньше цитат, технических слов и утверждений. Основываясь на этих результатах, исследователи создали компьютерную программу, использующую четыре самых сильных отличительных фактора фейковых новостей, — количество существительных и цифр, избыточность и количество слов — чтобы судить о достоверности статьи.
Программа, представленная на прошлогодней Международной конференции по веб-сетям и социальным медиа в Монреале, правильно отсортировала фальшивые новости от действительных в 71% случаев (программа, которая сортировала фальшивые новости от истинного наугад, имела бы примерно 50-процентную точность). Хорн и Адали ищут дополнительные функции для повышения точности.
Вероника Перес-Розас, специалист по компьютерным технологиям из Мичиганского университета в Анн-Арборе, и ее коллеги сравнили 240 оригинальных и 240 поддельных статей. Как и Хорн с Адали, команда Перес-Росас нашла больше наречий в фейковых новостных статьях. Поддельные новости в этом анализе, представленные на arXiv.org в 2017 году, также использовали более позитивные фразы и выражали большую уверенность в изложенном.
Исследование сотен статей показало стилистические различия между подлинными и выдуманными новостями. Реальные истории содержали больше языкового разнообразия, тогда как выдуманные выражали большую уверенность.Слова, часто использующиеся в правдивых новостях:
- «думаю», «знаю», «полагаю» — слова, которые выражают ход мысли;
- «работа», «класс», «босс» — слова, сопряженные с работой;
- «нет», «без», частица «не» — негативные слова;
- «но», «вместо», «против» — слова, которые выражают противопоставление;
- «процент», «большинство», «часть» — слова, выражающие эквивалентность.
- «всегда», «никогда», «доказано» — слова, которые обозначают уверенность;
- «разговор», «нам», «друг» — слова социального взаимодействия;
- «счастливый», «милый», «хороший» — слова, которые выражают позитивные эмоции;
- «относится», «знать», «должен» — слова, относящиеся к рациональным процессам;
- «будет», «готовится», «скоро» — слова, направленные на будущее.
Как только программа сгруппировала статьи по подобию, исследователи отметили 5% всех статей как фактические или ложные. Из этой информации алгоритм, описанный на arXiv.org, предсказал метки для остальных немаркированных статей. Команда Папалексакиса проверила на этой системе 32 тыс. реальных и 32 тыс. поддельных статей, которые были опубликованы в Twitter. Программа правильно вычислила около 69% постов.
Религиозные посты смущают компьютерные алгоритмы
Верно, около 70% контента — это недостаточная точность, чтобы доверять программам проверки новостей. Но детекторы фейковых новостей могут показывать предупреждение о возможном обмане, когда пользователь открывает подозрительную историю в веб-браузере. Аналогичный принцип работает, когда пользователь собирается посетить сайт без сертификата безопасности.
Первым шагом в борьбе с фейковыми новостям могут стать специальные «ищейки», работающие на базе платформ социальных сетей. Их цель — найти подозрительные новостные ленты и отправить их на проверку людям. Сегодня Facebook учитывает при выборе того, какие истории нужно проверять, обратную связь — например, от тех пользователей, кто публикует ложные комментарии или сообщает, что статья неверна. Затем компания отправляет эти истории «профессиональным скептикам» на FactCheck.org, PolitiFact или Snopes для проверки. Но Facebook открыт для использования и других сигналов для более эффективного поиска лжи в интернете, утверждает пресс-секретарь компании Лорен Свенссон.
Как полагает Хорн, как бы хорошо компьютеры не находили фейковые новости, эти системы не должны полностью заменять «человеческие» проверки фактов. Окончательное решение о том, является ли история ложной, может потребовать более тонкого понимания, чем компьютерный анализ.
Существует огромная серая шкала дезинформации, — рассказывает Хулио Амадор Диас Лопес, компьютерный ученый и экономист из Imperial College London. Это спектр, включающий в себя истину, извлеченную из контекста, пропаганду и заявления, которые практически невозможно проверить. Например, религиозные убеждения могут быть слишком жестким фильтром для компьютеров.
Писатель Снайпс Каспрак представляет, что будущее проверки фактов будет напоминать перевод с помощью компьютера. Во-первых, автоматическая система забивает черновик перевода. Но человеку по-прежнему приходится пересматривать этот текст для проверки пропущенных деталей, например, ошибок орфографии и пунктуации или слов, с которыми программа просто ошиблась. Точно так же компьютеры могут собирать списки подозрительных статей для людей, чтобы их проверить, говорит Каспрак, подчеркивая, что люди все равно должны вынести окончательное решение: содержится в новости правда или ложь.
Люди и фейки
Даже когда алгоритмы станут более «проницательными» и будут отмечать поддельные статьи, нет никакой гарантии, что создатели фейковых новостей не повысят ставки, чтобы ускользнуть от обнаружения. Если компьютерные программы призваны скептически относиться к рассказам, которые чрезмерно позитивны или выражают определенную уверенность, то авторы могут соответственно усовершенствовать свои стили написания.
"Поддельные новости, как вирус, могут развиваться и обновляться, — отмечает Дацин Ли, ученый, исследующий сети, из Университета Бейхан в Пекине. Он занимался анализом поддельных новостей в Twitter. К счастью, новости можно больше судить по факту, нежели по их содержанию. И другие контрольные признаки ложных новостей гораздо сложнее подделать, а именно — способы их привлечения аудитории.


Хуан Цао, ученый из Института вычислительной техники при Китайской академии наук в Пекине, исследовал китайскую версию Twitter — Sina Weibo. Он обнаружил, что определенная часть твитов о конкретной новости является хорошим показателем правдивости информации. Команда Цао построила систему, которая объединяла твиты, где обсуждают конкретное новостное событие, а затем сортировала эти сообщения по двум группам: на те, которые выражают поддержку истории, и те, что против нее.
Система рассматривала несколько факторов для оценки достоверности этих комментариев. Если, например, пост был сосредоточен на локальном событии, а пользователь был географически близок, его комментарий считается более достоверным, чем мнение пользователя, живущего далеко. Если пользователь долгое время находился в состоянии покоя и неожиданно начал публиковать сообщения об одной истории, это ненормальное поведение подсчитывается против доверия пользователя. Посредством взвешивания поддержки и скептических твитов программа решала, может ли конкретная история быть фальшивой.
Группа Цao проверила эту технику на 73 реальных и 73 поддельных рассказах, обозначенных таковыми государственным агентством новостей «Синьхуа» в Китае. Алгоритм рассмотрел около 50 тыс. твитов об этих историях на Sina Weibo и правильно распознал фальшивые новости примерно в 84% случаев. Команда Цао представила результаты в 2016 году в Фениксе на конференции «Ассоциация за развитие искусственного интеллекта».
Де Альфаро и его коллеги также сообщали в Македонии на Европейской конференции по компьютерному обучению принципам работы с базами данных, что лженовости можно отличить от настоящих на основе того, каким пользователям в Facebook нравятся эти истории.
Вместо того, чтобы смотреть, кто реагирует на статью, компьютер может проследить, как история распространяется в социальных сетях. Ли и его коллеги изучали связи репостов, которые были сделаны из сообщений с новостями в социальных сетях. Исследователи проанализировали сети репостов около 1,7 тыс. поддельных и 500 настоящих новостных материалов на Weibo, а также около 30 поддельных и 30 настоящих новостных сетей в Twitter.
На обоих сайтах в социальных сетях команда Ли обнаружила, что большинство людей склонно пересказывать настоящие новости из одного источника в то время, как поддельные новости, как правило, распространяются больше через людей, делающих репосты.
Типичная сеть реальных репортажей и новостей больше похожа на звезду, но поддельные новости имеют сеть в виде дерева, уверен Ли. Это подтвердилось, даже когда команда Ли проигнорировала новости, изначально опубликованные известными официальными источниками, например, самими новостными агентствами.
 |
| В Twitter большинство людей, постящих (красные точки) реальные новости, получают его из одного центрального источника (зеленая точка). Поддельные новости распространяются больше через людей, переходящих с других ссылок. |
Нельзя маркировать ложь
Как справиться с дезинформацией, попавшей в социальные сети? Этот вопрос остается открытым. Простая чистка фиктивных статей из новостных лент, вероятно, не самая лучшая идея.
«Платформы для социальных сетей, обеспечивающие такой уровень контроля над тем, что могут видеть юзеры, будут похожи на тоталитарное государство, — отмечает Мерфи Чой, аналитик данных SSON Analytics в Сингапуре. — Это будет очень неудобно для всех».
Платформы могут помещать предупреждающие знаки к постам с дезинформацией. Но маркировка историй может иметь неудачный «мнимый эффект правды». Люди могут больше доверять любым историям, которые не помечены как ложные, независимо от того, были они проверены или нет, согласно мониторингу, опубликованному в Исследовательской сети социальных наук учеными, занимающимися поведением человека, Гордоном Пенникуком из Университета Регины в Канаде и Дэвидом Рэндом из Йельского университета.
Вместо того, чтобы удалять истории, Facebook показывает их разоблачение ниже в новостных лентах пользователей, которые могут сократить ссылки и репосты ложной статьи на 80%, утверждает представитель компании Свенссон. Facebook также отображает статьи, которые развенчали ложные публикации, когда пользователи сталкиваются со связанными историями, хотя эта техника может иметь неприятные последствия.
В исследовании пользователей Facebook, которые любят обмениваться новостями о Всемирном заговоре, Золло и его коллега Уолтер Кватроциокки обнаружили, что после того, как заговорщики взаимодействовали с развенчивающими ложь статьями, эти пользователи фактически увеличили свою активность на страницах заговора на Facebook. Исследователи сообщили об этом в июне в «Сложных явлениях распространения в социальных системах».
Предстоит много работы по обучению компьютеров и людей для распознавания фальшивых новостей. Как говорится в старой поговорке, ложь успеет встретиться со всем миром, пока правда надевает свою обувь. Но компьютерные алгоритмы с их острым зрением могут по крайней мере замедлять распространение поддельных историй, выступая в виде гирь на лодыжках.
По материалам Business Insider, Reuters